Built for
Microsecond Execution
Every layer of Nanoconda's stack - from hardware to protocol - is engineered to remove latency. Here's exactly how.
Latency Has Two Enemies
To build a fast DMA platform, you need to defeat both - not just one.
1. Physics
Light travels through fiber optic cable at roughly 5 microseconds per mile. The further your algorithm is from the CME matching engine in Aurora, Illinois, the more inescapable latency you accumulate.
Every additional network "hop" - through a router, to a separate risk server, across a datacenter - adds latency that cannot be engineered away. Physics is non-negotiable.
2. Technology
Even at the ideal physical location, software overhead can introduce hundreds of microseconds. The Linux kernel, TCP/IP stack, context switches, memory copies, and locks all eat latency one layer at a time.
Most off-the-shelf FIX engines and DMA platforms were not built for nanosecond-scale execution. They pay unnecessary overhead at every hop in the data path.
How We Solve Both Problems
Three engineering decisions that eliminate latency at every level of the stack.
{{ p.body }}
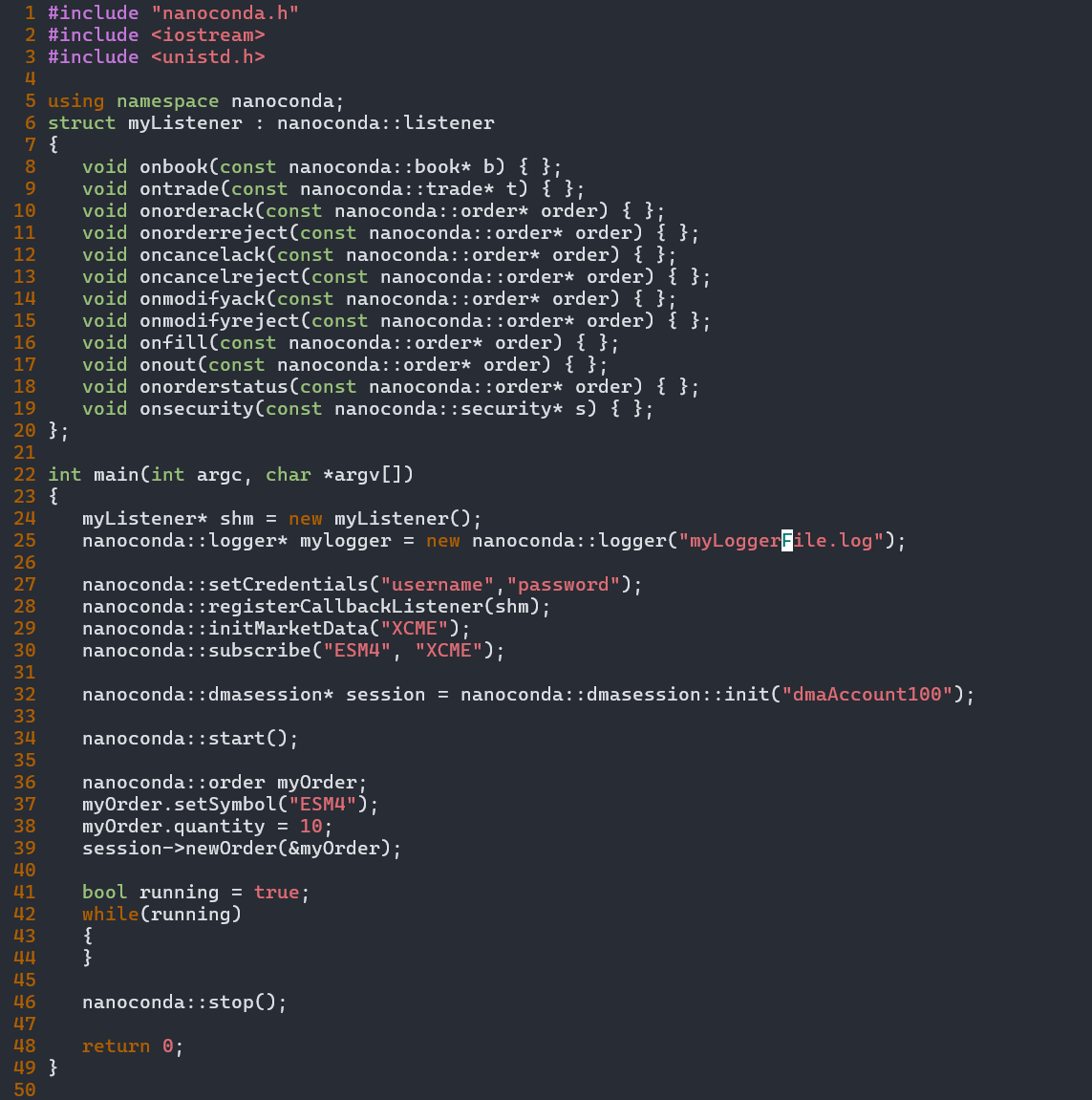
Simple API.
Institutional Performance.
Despite the complexity underneath - kernel bypass, shared memory, lock-free queues - the API your quants write against is clean and minimal. Implement callbacks, call nanoconda::start(), and your strategy is live.
The same code runs in the simulator, against PCAP or DataBento DBN replay, and in production - no environment-specific branches, no integration rewrites between stages.
Full documentation at nanoconda.com/docs.
Request a Technical WalkthroughCME-Native Protocol Support
Full compliance with current CME exchange specifications - maintained as standards evolve.
{{ p.description }}
- {{ pt }}
CME Colocation, Managed for You
Your strategy runs at the exchange - without you managing a single server.
What's in the Colocation Container
The Colocated Container plan gives you a dedicated, fully managed environment inside CME's colocation facility - physically adjacent to the exchange's matching engines.
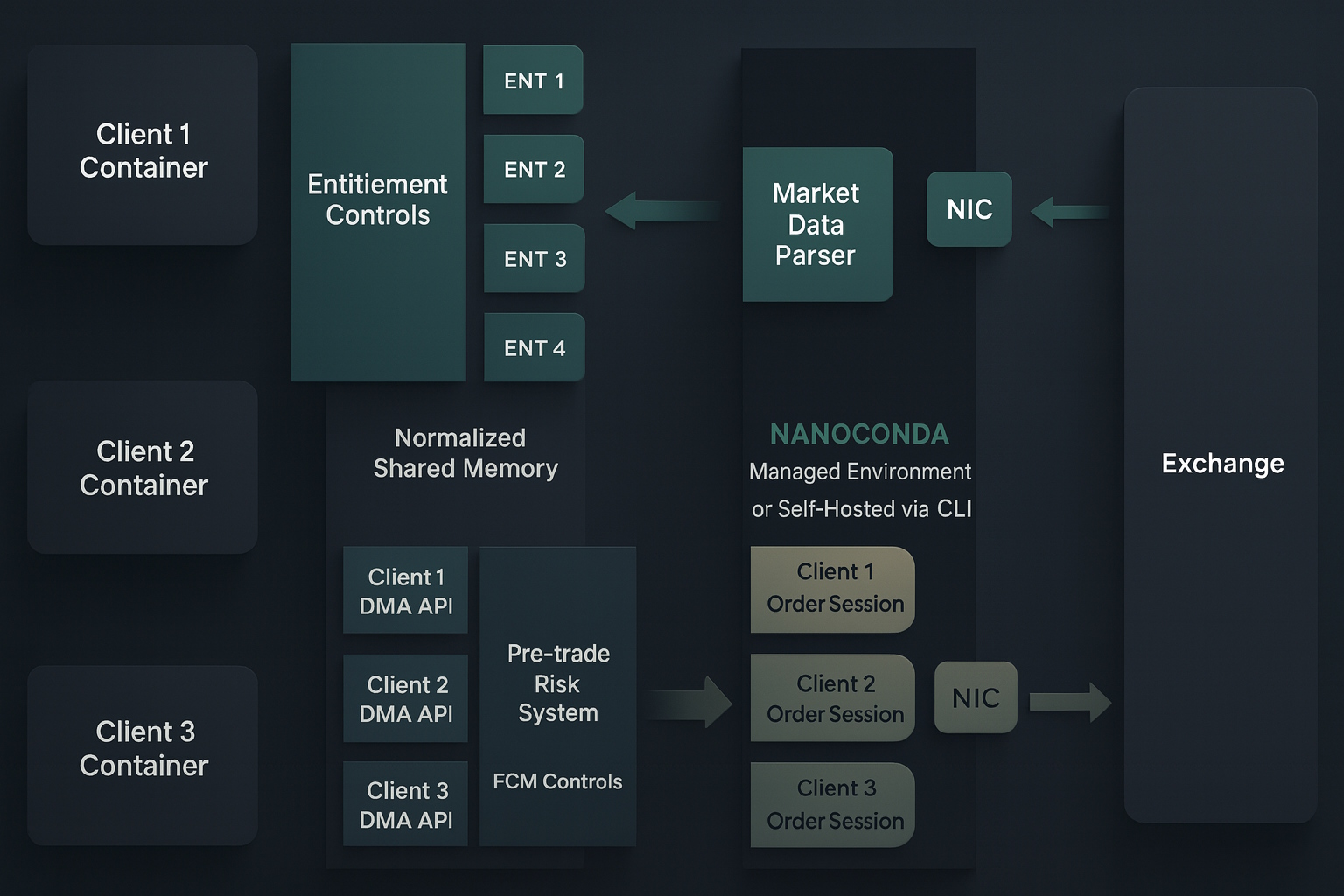
Built for Production Environments
Institutional security, audit trails, and isolation - required by any serious trading operation.
{{ s.body }}
Technical Specifications
Want the full technical deep-dive?
Schedule a call with our engineering team for a detailed architecture walkthrough.